1) Chaque pixel peut prendre 224 valeurs (états)
possibles. Comme on suppose que les pixels sont indépendants les
uns des autres, le nombre détats possibles dun système
de 1000*1000 pixels est de
N = (224 )1000 000 = 2 24 000 000 = 10 7 200 000
2) durée de traitement dune image : t = 10 - 12 s
durée totale : T = t N = 10 7 200 000 - 12
s ;
ou T = 10 7 200 000 - 30 fois lâge actuel de lunivers : on est carrément hors du temps.
3) avec une image 10*10 sur 1 bit par pixel : N = 2 100
= 10 30
durée totale T = t N = 10 30 - 12 s = 10 18
s = 31 milliards dannées, soit environ deux fois lâge actuel
de lunivers.
On peut estimer de la même façon la durée quil faudrait pour craquer par force brute une clé informatique codée sur 100 bits.
Si lon prend comme mesure de linformation G le nombre de bases, on
a
G = log4 (N)
Dautre part, si lon applique la formule
G = k lb (N)
on trouve
k = log 4 (N) / log 2 (N)
k = ln 2 / ln 4 = 0,5.
On retrouve ce résultat intuitivement car une base (ou codon) ADN peut prendre 4 valeurs, donc vaut 2 bits.
Réflexions ...
Quest-ce qui contient le plus dinformation dans le corps hmain :
le cerveau ou le code génétique ? (et ne me dites pas : Ca
dépend qui ! )
H = S / (Kb ln 2) car lb x =
ln x / ln 2
H = 1,046 10 23 S
Un Joule par Kelvin (unité dentropie thermodynamique) correspond
à 10 23 bits environ.
Réflexions ...
y a-t-il une raison physique pour que cette quantité soit commensurable
avec le nombre dAvogadro ?
Peut-on exprimer le nombre de bits par atome à une température
donnée ? Quelle serait la relation avec les états dénergie
dans un atome ?
Parmi les mémoires suivantes, laquelle est la plus compacteen
bits par kg :
- livre
- DVD
- chip RAM de 1 Gigabit
- synapse de neurone
- ADN
Comment évaluer la limite théorique à la capacité
dune mémoire ?
Si lon observe lun des deux événements, on a :
I(x1) = - lb P(x1) ou bien
I(x2) = - lb P(x2) .
Si lon observe les deux événements, on a :
I(x1, x2) = - lb P(x1, x2)
.
Comme les événements x1 et x2 sont indépendants,P(x1,
x2) = P(x1) P(x2), donc
I(x1, x2) = - lb P(x1) - lb P(x2)
= I(x1) + I(x2) .
Si létat 1 a un proba P1, alors létat 2
a pour proba: P2 = 1 - P1.
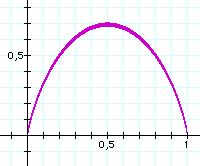
H(P1) = -P1 lb P1 - (1-P1) lb(1-P1)
H(P1) = f(x) / ln 2 avec:
x = P1 et f(x) = - [ x ln x + (1-x) ln (1-x) ]
cest une fonction symétrique par rapport à x = 1/2 car inchangée si lon remplace x par 1-x.
f(x) = - [ ln x + 1 - ln (1-x) + -1 ] = ln (1-x) - ln x
| x | 0 | 1/2 | 1 |
| f(x) | 0 | 1/ln2 | 0 |
| f (x) | +inf | 0 | -inf |
1) 1,45 M bits. Pour transmettre cette quantité
dinformation en 10 s il faut un débit de 145 k bits s- 1
. Cest trop pour la ligne considérée.
2a) h = - 0,01 lb 0,01 - 0,99 lb 0,99 = 0,081 bit
2b) Pour toute la page H = 117 k bits. Pour transmettre cette quantité dinformation en 10 s il faut un débit de : 11,7 k bits s- 1 . Cest possible avec un canal de débit 28,8 k bits s- 1 à condition dutiliser un codage proche de loptimal.
1) 256 niveaux, de 400 x 500 pixels => H = 8*400*500 = 1,6 M bit
2) Coder non pas la brillance dun pixel mais la différence de brillance entre deux pixels consécutifs.
P(0) = 1/2 ; P(1) = 1/4 ; P(-1) = 1/4 ;
Entropie : 1/2+1/2+1/2 = 1,5 bits par pixel au lieu de 8 sans
compression.
3) Pour améliorer encore la compression on peut combiner le codage précédent avec la différence entre un pixel et son homologue dans limage suivante. P(0) sera encore augmenté, doù une réduction de H.
1) Nombre moyen de bits par symbole avec le code utilisé
:
(2+3+...+27)/26 = 29/2 = 14,5
2) Entropie de la source : lb (27) = 4,75
3) Exemple de codage meilleur
binaire sur 5 bits: A->0001 ; B->0010 ; C->0011 ; D->0100 ; E->0101
etc.
On a alors 5 bits par symbole, ce qui se rapproche de lentropie de
la source.
4) gaffe au chat noir, il griffe *@!!
Démonstration :
Dans la suite,
le caractere : S devrait apparaitre
comme le caractere grec "Sigma" ou "Somme de".
le caractere : ? devrait apparaitre comme "inférieur
ou égal"
le caractere : * devrait apparaitre comme "supérieur ou
égal"
Soit Ui = Qi - Pi , la différence entre les deux probas.
S Pi lb Qi = S Pi lb (Pi + Ui )
S Pi lb Qi = S Pi lb [Pi (1 + Ui /Pi)]
S Pi lb Qi = S Pi [ lb Pi + lb (1 + Ui /Pi)]
S Pi lb Qi = S Pi lb Pi +S Pi lb (1 + Ui /Pi)]
or lb (1+x) = ln (1+x) / ln 2
et ln (1+x) ? x pour tout x => lb (1+x) ? x / ln 2 pour tout x.
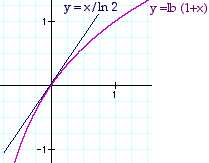
=> Pi lb (1 + Ui /Pi) ? Pi Ui /Pi
ln 2
=> S Pi lb (1 + Ui /Pi) ? (1/ ln 2) S Ui
or daprès le définition de Ui on voit que S Ui = 0.
=> S Pi lb (1 + Ui /Pi) ? 0 .
et en revenant à lexpression du départ cela implique :
Somme Pi lb Qi ? S Pi lb Pi ,
=> Somme Pi ( lb Qi - lb Pi) ? 0 ,
=> K = + Somme Pi lb (Pi /Qi ) * 0 .
Non, car le canal est bien discret, mais non sans mémoire
: La probabilité dune lettre dépend des précédentes,
par exemple la probabilité dun u après un q est bien
plus élevée que celle dun z après un q.
![]()
On a donc :
H(X) = 0,971 ; H(Y) = 1
M (X,Y) = M (X ) M (Y|X)

H (X, Y) = - Se Sr P(xe , yr ) lb [ P(xe , yr ) ]
H (X, Y) = 0,526 + 0,292 + 0,445 + 0,526 = 1,788
H (X|Y) = H (X, Y) - H(Y) = 0,788
I(X,Y) = H(X) - H (X|Y) = 0,971 - 0,788 = 0,183